.png&blockId=5f7573ad-6867-4d59-999e-722aced04aeb)


Medium
Given an integer array nums and an integer k, return the k most frequent elements. You may return the answer in any order.
Example 1:
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]
Plain Text
복사
Example 2:
Input: nums = [1], k = 1
Output: [1]
Plain Text
복사
Constraints:
•
1 <= nums.length <=
•
k is in the range [1, the number of unique elements in the array].
•
It is guaranteed that the answer is unique.
Follow up: Your algorithm's time complexity must be better than O(n log n), where n is the array's size.
My solution
일단 reduce로 해시맵을 대신해서 객체에 담으려고 했다. 근데 이렇게 만드니까 프로퍼티들이 enumerable 속성이 false인 채(이게 default라서)로 들어가서 배열화하는 게 불가능한 것 같다.
그래서 그냥 보장되는 해시맵을 사용한다음.
entries()를 이용해서 [프로퍼티 키, 프로퍼티 값]으로 하나씩 감싼다음 {}의 객체 리터럴로 감싼 형태로 만들었다.
그리고 이 객체 리터럴을 destructuring 하면 {}가 벗겨지고 이걸 []로 감싸면 배열이 된다.
이 배열을 2번째 원소인 프로퍼티 값(빈도수)에 따라 sort한 다음 map으로 1번째 원소만 남은 배열을 새롭게 반환한다. 이 반환된 것을 바로 slice로 k만큼 잘라서 리턴했다.
굉장히 좋은 성능이 나왔다.
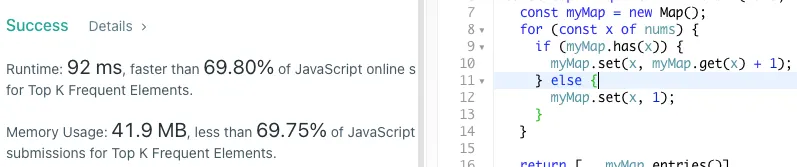
근데 훨씬 더 빠르면서 해시맵을 안 쓰고 객체 리터럴을 사용한 방식이 있었다. entries()를 쓰는 게 아니라 for...in 문을 사용해서 배열을 구성한다.
다른 사람 풀이
소스코드
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
const topKFrequent = function (nums, k) {
const myMap = new Map();
for (const x of nums) {
if (myMap.has(x)) {
myMap.set(x, myMap.get(x) + 1);
} else {
myMap.set(x, 1);
}
}
return [...myMap.entries()]
.sort((a, b) => b[1] - a[1])
.map(v => v[0])
.slice(0, k);
};
test('TC1', () => {
expect(topKFrequent([1, 1, 1, 2, 2, 3], 2)).toStrictEqual([1, 2]);
});
test('TC2', () => {
expect(topKFrequent([1], 1)).toStrictEqual([1]);
});
test('TC3', () => {
expect(topKFrequent([1, 1, 1, 2, 2, 3, 3, 3, 3, 3, 4], 2)).toStrictEqual([3, 1]);
});
JavaScript
복사
